

The idea of synthetic respondents in market research arises from a desire to simulate human responses using artificial intelligence. Instead of collecting data from real people, AI models trained on vast historical datasets of human behaviour, attitudes, and demographics generate “virtual” answers to survey questions. These systems promise faster turnaround times and drastically reduced costs. For research teams under financial or time pressure, the concept appears transformative. However, a closer examination reveals deep methodological and philosophical flaws that make synthetic respondents unreliable for genuine consumer insight.
How Synthetic Respondents Work
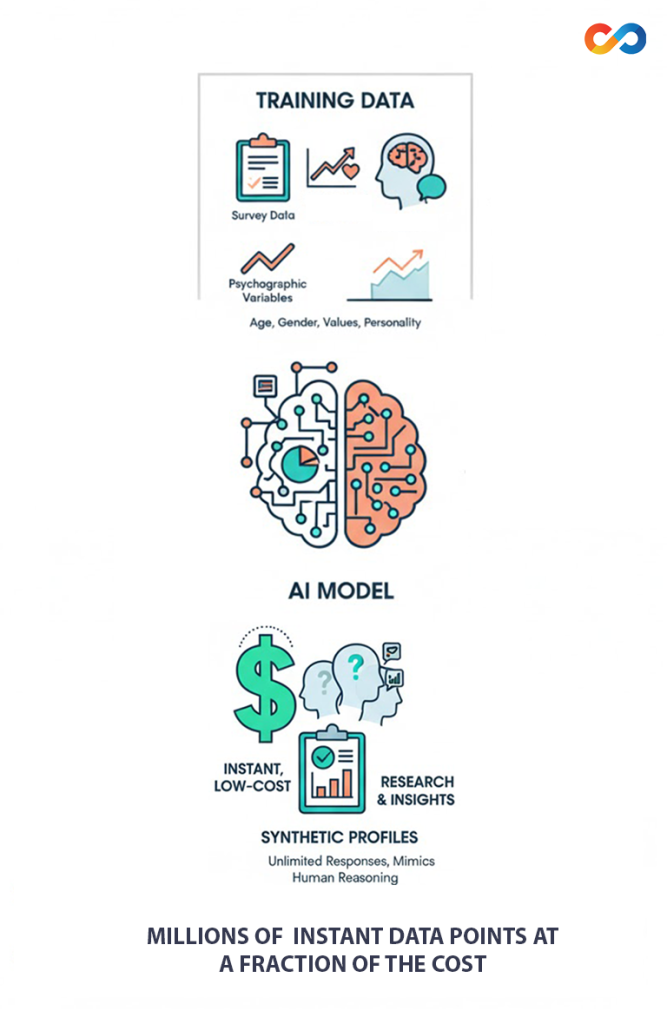
Synthetic respondents are built by training machine-learning algorithms on existing survey data, behavioural datasets, and psychographic variables. The model identifies patterns in how different kinds of people, segmented by age, gender, values, or personality traits, tend to respond to specific questions. Once trained, the system can generate an unlimited number of “responses” that appear to mimic human reasoning. Some models incorporate simplified psychological theories such as the Big Five personality traits in an attempt to give coherence to simulated behaviour. The attraction is clear: millions of instant data points at a fraction of the cost of traditional fieldwork.
Such systems might appear useful for early hypothesis testing or scenario exploration, particularly when the subject matter can be anchored to well-established attitudes or behaviours. Yet their reliability collapses when the topic extends beyond familiar territory. New products, social trends, cultural shifts, or political contexts fall outside the training distribution of the data, leaving models to fabricate results that merely look plausible. The moment the stimuli diverge from what the model has previously seen, predictions become statistical noise.
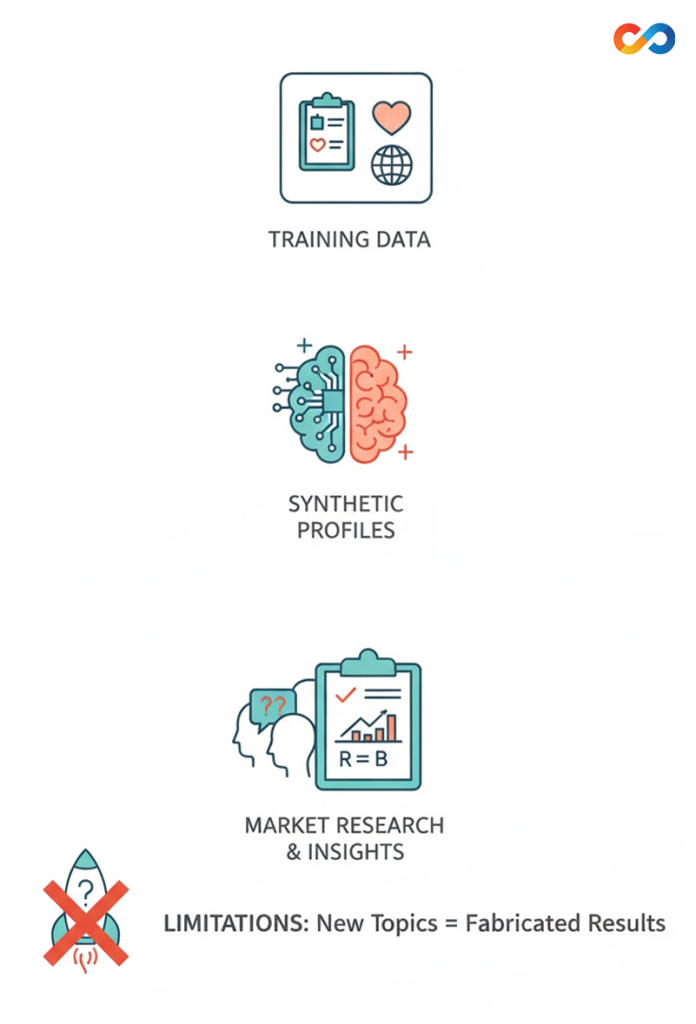
The Limits of Synthetic Modelling
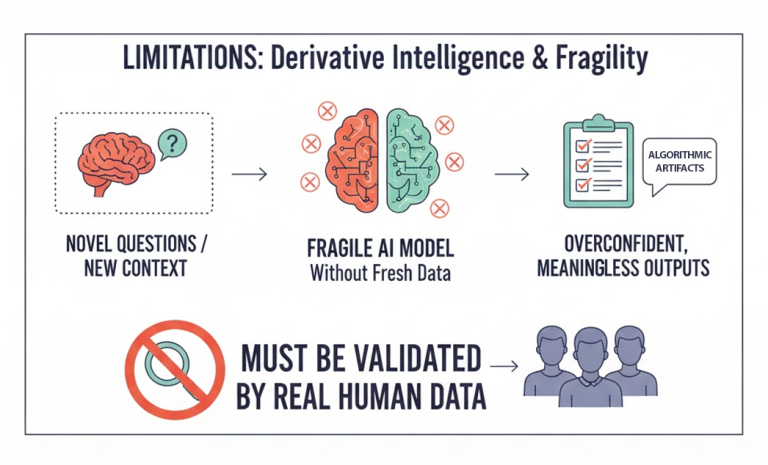
The greatest limitation of synthetic respondents is that their intelligence is entirely derivative. They are only as good as the data and theoretical assumptions used to build them. Novel questions, precisely those that most market research seeks to answer, expose the fragility of their design. Without fresh context, models tend to produce overconfident but meaningless outputs. In practice, any insight drawn from synthetic respondents must be validated against real human data; otherwise, researchers risk mistaking algorithmic artefacts for genuine consumer sentiment.
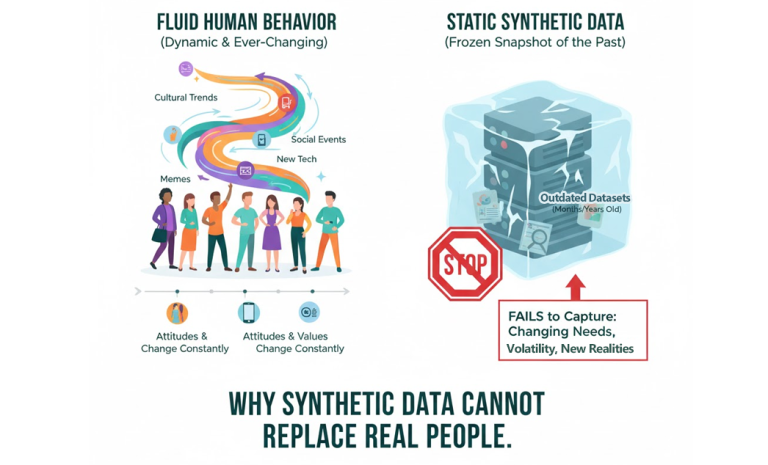
Human behaviour itself is fluid. Attitudes and values change constantly under the influence of cultural trends, economic shifts, and social events. Fashion cycles, new technologies, memes, and crises continually reshape public perception. Synthetic datasets, by contrast, represent a frozen snapshot of the past. Data collected even a few months earlier may no longer reflect current consumer reality. The very reasons companies commission research, to understand changing needs, to anticipate volatility, are the same reasons synthetic data cannot replace real people.
The Problem of Surface-Level Insight
Another critical weakness lies in what synthetic models can actually “know.” Most consumer decisions are driven not by conscious reasoning but by unconscious emotion and intuition. Estimates suggest that up to 95% of purchasing behaviour originates from these implicit processes. Because AI systems learn only from explicit, self-reported data, what people say they think or feel, they miss the non-conscious drivers that determine real action. True understanding requires methods such as implicit association tests or affective priming, which capture the emotional undercurrents beneath stated preference. Synthetic respondents cannot replicate this dimension, meaning their outputs at best commoditise surface-level insight and at worst mislead decision-makers.
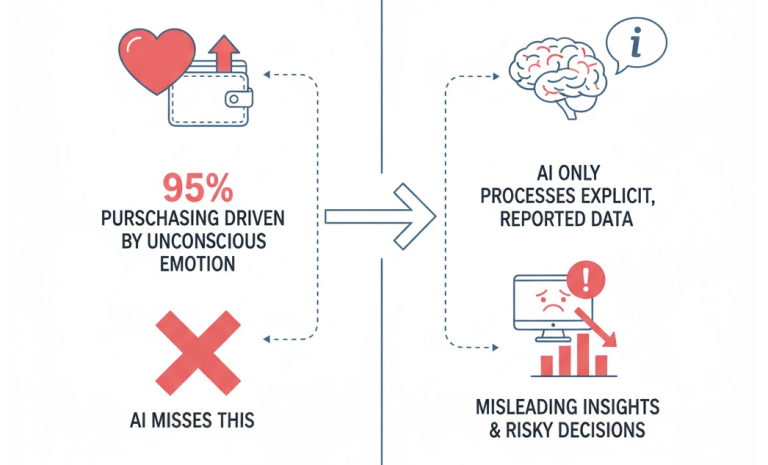
The distinction between declared intent and unconscious motivation is fundamental. Consumers often rationalise their choices after the fact, offering reasons that sound plausible but do not reflect their true psychological drivers. AI trained on these rationalisations inherits the distortion. It therefore reproduces the illusion of understanding while remaining blind to the hidden dynamics that move markets.

The Scale and Theoretical Barriers
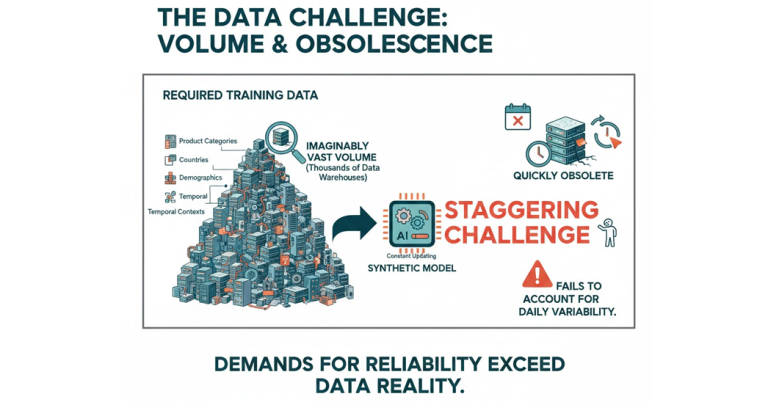
Even assuming that researchers could gather enough training data, the challenge would be staggering. To construct a reliable model, one would need continuously updated behavioural data across thousands of product categories, countries, demographic groups, and temporal contexts. Each market segment and cultural micro-environment adds another layer of complexity. The data volume required would be unimaginably vast, on the order of thousands of data warehouses, and still would not account for the daily variability of human life. Without constant updating, any model would quickly become obsolete.
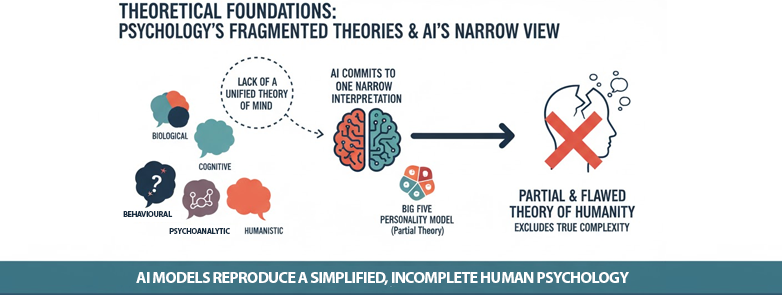
A deeper problem concerns the theoretical foundations of these models. Psychology, the discipline most directly concerned with human behaviour, lacks a single unified theory of mind. It consists of competing schools, biological, cognitive, behavioural, psychoanalytic, humanistic, each with its own assumptions. Unlike physics or biology, psychology offers no overarching framework that unites its subfields. Any synthetic model that purports to represent “the human mind” must therefore commit to one narrow interpretation while excluding others. Many use the Big Five personality model primarily because it is free to use, not because it is scientifically definitive. As a result, synthetic respondents embody a partial and sometimes flawed theory of humanity.
Why Real Data Still Matters

Real data derived from actual people captures the richness, inconsistency, and emotional variability that define human experience. It reflects current events, cultural nuance, and shifting sentiment in real time. Synthetic data, by contrast, smooths out this variance, creating an artificial “average consumer” who does not truly exist. Such averaging removes the outliers and anomalies that often hold the most valuable insight. The danger is that brands relying on synthetic respondents will act on oversimplified representations, leading to poor strategic choices.
The validity of market research depends on its connection to the living reality of human behaviour. While synthetic respondents may serve as a supplementary tool for internal ideation or to test scenarios grounded in known data, they cannot replace the empirical engagement with real participants. Their use should be limited to exploratory analysis where the cost of error is low. For any form of custom or decision-critical research, new product testing, advertising evaluation, or attitude measurement, real human data remains indispensable.
Data Ownership and Ethics
Finally, there are ethical and legal concerns. Most consumer data used to train these models originates from proprietary research commissioned by brands. Such data is confidential and legally protected; using it to train synthetic systems without consent would constitute theft and plagiarism. The publicly available data suitable for training is minuscule and narrowly focused, making it insufficient for comprehensive modelling. This further limits the realism and validity of synthetic respondents.
Synthetic respondents offer an illusion of precision and speed but lack the fundamental qualities that make research meaningful: real-time human variability, unconscious motivation, and contextual relevance. They depend on outdated information, limited theoretical models, and vast assumptions about human predictability. The method flattens complexity into statistical averages and risks misleading organisations that rely on its results. While useful for simulating “what-if” scenarios or supplementing established datasets, synthetic respondents cannot substitute for real human research. At best, they reflect yesterday’s understanding of people, not today’s reality.
Epilogue
Thirty-five years ago, I was sitting in one of the world’s first AI labs — the Neural Systems Engineering Lab at Imperial College London — discussing the future of artificial intelligence. Around me were mathematicians, linguists, biologists, computer scientists, neuroscientists, psychologists, and electronic engineers. As we explored what might be possible, two thoughts struck me.
First, people without formal training in psychology almost always underestimate its complexity. They assume it is a unified, advanced discipline that can already explain most of human behaviour. It isn’t. Psychology is fragmented into competing perspectives and models of what makes a human being. Researchers still cannot agree on what “mind” even means, nor can they explain how physical matter like the brain gives rise to conscious experience.
Second, people who work in AI tend to be natural optimists. Many believe that a large enough deep learning model, fed with enough data, can solve any problem. In my experience, both of these beliefs are false. If you assume psychology can already explain human behaviour, you might also assume that superintelligence is simply a matter of scaling up data. But we don’t yet understand how people think, so AI models are not built from a psychological foundation. Instead, they emerge from mathematics, computer science, engineering, and large-scale experimentation.
Back then, we worked on what were called “toy problems” because computing power was limited. Today, across CPU, memory, storage, graphics, and I/O, computers are roughly 100 million to 1 billion percent more powerful than they were in 1990. Advances of that scale have made large language models and the new generation of chat-based AIs possible. Yet even with such immense processing power, machines still cannot match human cognition. Because their architectures do not generate thought or action as humans do, they remain fundamentally different from us — powerful, but not sentient.
AI is already immensely useful, and it’s improving fast. But in market research — where we need to understand how people truly think, not just approximately — relying on AI alone to generate insights risks a strange outcome: we might end up designing products for AI, and not for humans.
Bullet-point summary
- Definition: Synthetic respondents are AI-generated models that simulate survey answers using historical and behavioural data.
- Process: Models learn response patterns from past surveys, demographics, and psychographics, producing virtual participants.
- Advantages: Fast, cheap, scalable; useful for exploratory or pre-fieldwork testing.
• Limitations :
- Dependent on training data quality and context relevance.
- Fail on novel topics or new product categories outside prior data distribution.
- Generate biased or “hallucinated” insights when extrapolating.
- Require validation against real human data.
• Human variability:
- Consumer attitudes and emotions change with time, culture, and events.
- Static models cannot reflect real-time shifts or contextual nuance.
- Outdated data quickly loses validity.
• Psychological depth
- Most consumer decisions are driven by unconscious processes.
- AI models only reflect explicit, self-reported data and miss implicit motivations
- Implicit response tests reveal hidden drivers inaccessible to synthetic systems.
• Data and theory constraints:
- Accurate modelling requires unmanageably vast, regularly updated datasets.
- Psychology lacks a single unified theory of behaviour; models commit to narrow, flawed frameworks.
- Popular models like the Big Five are chosen for cost, not scientific adequacy.
- Conclusion: Synthetic respondents flatten meaningful human variance and ignore cultural signals. They may aid ideation but cannot replace real respondents for valid, custom market research.
Latest Posts
Join Our Newsletter
Subscribe to our email newsletter to keep up to date with our latest insights, news, and findings on market research, implicit testing and our occasional psychological ‘neuro-nuggets’ of wisdom.
Our blog

Split Second Research x On-Target Marketing Solutions
We are pleased to announce a strategic partnership between Split Second Research (UK) and On-Target Marketing Solutions for Asia-Pacific.
Dr. Salim Khubchandani, who leads On-Target Marketing Solutions
The risk of believing you already understand your customers
We talk a lot about the consumer truth gap, which is the gap between what people say they are going to do and how
AI-assisted predictive modelling at Split Second Research
Many of our clients have built up a rich body of research over time. A common question we hear is how to get more value